
If you’re getting ready for a data engineer interview, you might feel overwhelmed. The good news? You don’t need to memorize everything. You just need to understand the basics and how to talk about them. This guide walks you through real-world data engineer interview questions, tools you’ll use, cloud platforms, and what to expect. Whether you’re a beginner or a seasoned pro, this article is for you.
What Does a Data Engineer Do, Really?
A data engineer is someone who builds systems to collect, clean, and move data so that others—like data analysts and data scientists—can use it. Think of them as the builders who set up the plumbing of the data world. Without them, companies wouldn’t be able to manage all the data they collect.
They work with large datasets, design pipelines, manage databases, and ensure everything runs smoothly behind the scenes. Data engineers also make sure the data is in the right format, safe, and easy to access for business intelligence and machine learning tasks. They use tools like SQL, Python, Apache Spark, ETL frameworks, and work on platforms like AWS, Google Cloud, or Azure.
Must-Know Data Engineer Interview Questions
When you walk into a data engineer interview (or log into one), you’ll likely get asked a mix of technical, conceptual, and even behavioral questions. Interviewers want to know if you can do the job but also how you think and solve problems.
Some common data engineer interview questions include:
- How would you design a data pipeline from scratch?
- What is the difference between batch processing and stream processing?
- Can you explain data normalization and denormalization?
- How would you optimize a slow-running SQL query?
- What tools have you used for ETL?
- How do you handle dirty data?
These questions aren’t just about facts—they’re about your real-world understanding. Interviewers are trying to see how comfortable you are working with data and building solutions that can scale.
What is ETL and Why is it Important?
ETL stands for Extract, Transform, Load. It’s a key part of what data engineers do daily. First, you extract data from different sources—databases, APIs, files, or logs. Then, you transform it—clean it up, format it, maybe aggregate or filter it. Finally, you load it into a data warehouse or a destination where it can be analyzed.
Understanding ETL is crucial in any data engineer interview. You might be asked questions like:
- What tools have you used for ETL? (Answers could be Apache NiFi, Airflow, Talend, or AWS Glue.)
- How do you ensure data quality during transformation?
- Can you describe a real ETL pipeline you’ve built?
This is your chance to show that you understand not just the theory but how ETL works in practice—especially when dealing with large datasets.
What’s the Difference Between Data Engineers and Data Scientists?
This is a popular interview question, and the key is to explain it in simple terms. A data engineer builds the systems that move and store data. A data scientist uses that data to find patterns, make predictions, and support decision-making.
Think of it like this: Data engineers build the kitchen; data scientists cook the food. Engineers focus on performance, scalability, and architecture, while scientists focus on analysis, modeling, and insight.
How Do You Handle Missing or Bad Data?
This is one of the most practical and realistic interview questions. Missing or bad data is a part of everyday life in data engineering. Good answers include:
- Identifying missing values using data profiling tools or SQL queries
- Replacing null values with defaults or averages (imputation)
- Removing rows or columns depending on the data’s importance
- Logging errors and sending alerts when data quality drops
Tools like Great Expectations, Pandas, and Airflow are often mentioned in real-world data workflows for data validation and transformation.
Easy Technical Questions You Should Know
Not every interview question is super complex. Some are basic, but they still matter. These often include:
- What is a primary key and a foreign key?
- Explain normalization in databases.
- What’s the difference between INNER JOIN and LEFT JOIN?
- What are the types of indexes in SQL?
- What’s the difference between CSV and Parquet file formats?
These questions help interviewers know that you’ve covered your basics and can work in production environments.
SQL Questions You’ll Likely Hear
SQL is the backbone of data engineering, and interviewers often go deep here. Expect to answer:
- Write a query to find the second highest salary in a table.
- Explain window functions and give an example.
- What is the difference between GROUP BY and PARTITION BY?
- How do you optimize a SQL query with multiple JOINs?
- What’s the difference between WHERE and HAVING?
You should also know how to work with CTEs (Common Table Expressions), subqueries, indexes, and execution plans. Practicing real queries on platforms like LeetCode, Hackerrank, or StrataScratch helps a lot.
Cloud Platforms – What You Should Know
Most companies now operate in the cloud, so interviewers want to know if you’ve worked with cloud platforms like:
- AWS (especially S3, Redshift, Glue, Lambda)
- Google Cloud (BigQuery, Dataflow, Cloud Functions)
- Microsoft Azure (Data Factory, Synapse Analytics)
You might be asked questions like:
- How would you set up a data pipeline on AWS?
- What’s the difference between Redshift and Snowflake?
- How do you manage data access and security in the cloud?
Make sure you also know about IAM roles, buckets, and cloud-native ETL tools.
Simple Cloud Tools You Might Use
In interviews, naming specific tools shows experience. Some of the most common cloud tools for data engineers include:
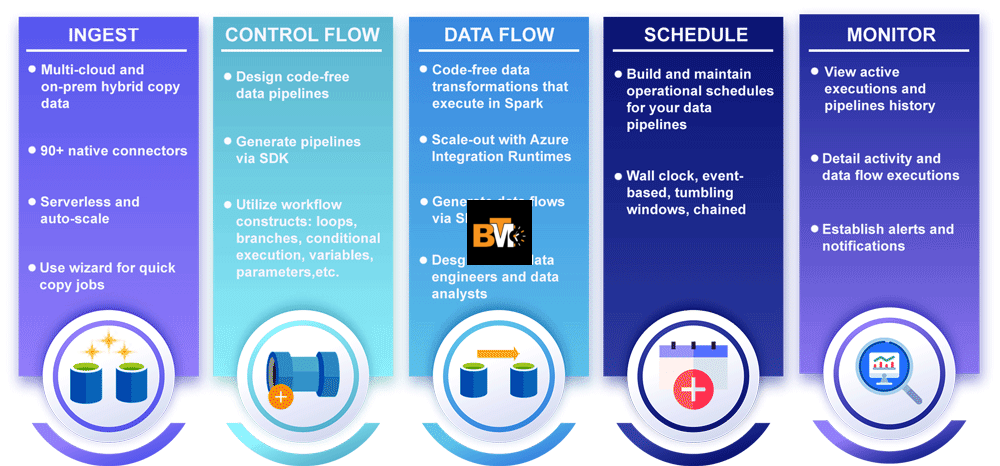
- AWS Glue – for serverless ETL
- Apache Airflow – for pipeline scheduling
- Google BigQuery – serverless data warehouse
- Azure Data Factory – integration service for ETL
- Snowflake – cloud-based data warehouse
- dbt (data build tool) – for transformation in ELT
You might be asked: How do you schedule jobs in Airflow? Or how would you load data from S3 to Redshift? The more examples you can share, the better.
What’s a Data Pipeline in the Cloud?
A data pipeline in the cloud is a set of steps that move and transform data from one place to another using cloud services. A common pipeline might:
- Ingest data from APIs, logs, or user inputs into S3.
- Use AWS Glue or Airflow to transform the data.
- Load it into Redshift or Snowflake.
- Set alerts and monitoring using CloudWatch or DataDog.
In interviews, break it down simply. Describe the tools, their roles, and how data flows end-to-end. Show that you know not just how, but why each tool fits.
Python & Scripting Basics for Interviews
Python is a must-know for data engineers. Interviewers may ask:
- How do you read large CSV files in Python?
- What’s the difference between a list and a tuple?
- How would you use Pandas to clean a dataset?
- What’s a lambda function and where have you used it?
Knowing how to use Pandas, NumPy, and even PySpark is important. You don’t need to be a software engineer, but you should be comfortable with scripts that move and clean data.
Behavioral Questions You Should Prepare For
Yes, soft skills matter too. Common behavioral questions include:
- Tell me about a time you had a data quality issue. What did you do?
- Have you ever disagreed with a data scientist or stakeholder? How did you handle it?
- Describe a project you’re proud of.
- How do you stay up-to-date with new tools and trends?
Use the STAR method (Situation, Task, Action, Result) to answer. Be honest, clear, and don’t exaggerate.
Tips to Get Ready for a Data Engineer Interview
Preparation is key. Here are a few tips to boost your chances:
- Practice SQL daily – use real-world problems
- Build mini projects – pipelines with Airflow, ETL scripts in Python, etc.
- Learn one cloud platform well – AWS, GCP, or Azure
- Study system design – know how to design a pipeline end-to-end
- Mock interviews – do them with friends or online platforms
Keep learning. Even if you don’t get the first job, every interview will teach you something new.
The Bottom Line
Data engineering isn’t just about coding—it’s about solving problems with data. If you can understand the tools, explain your work, and stay curious, you’ll do well. The most successful candidates aren’t the ones with perfect answers—they’re the ones who can communicate clearly, think critically, and show real experience.
So whether you’re new or experienced, just remember: prepare, practice, and stay calm. The right opportunity is out there, and with the right prep, you’ll be ready when it comes.